SQL TUNER for PostgreSQL에서는 BRIN 인덱스에 대해 다음과 같이 간단히 소개만하고 넘어갔다.
•
BRIN(Block Range Index)
◦
용도: 테이블이 매우 크고, 데이터가 순서대로 쌓이는 경우
▪
로그 테이블의 시간 컬럼(계속 증가), 주문 번호(계속 증가)
◦
특징: 크기가 작고 관리 비용이 낮음. 단, 데이터가 무작위로 저장되면 효율이 떨어짐
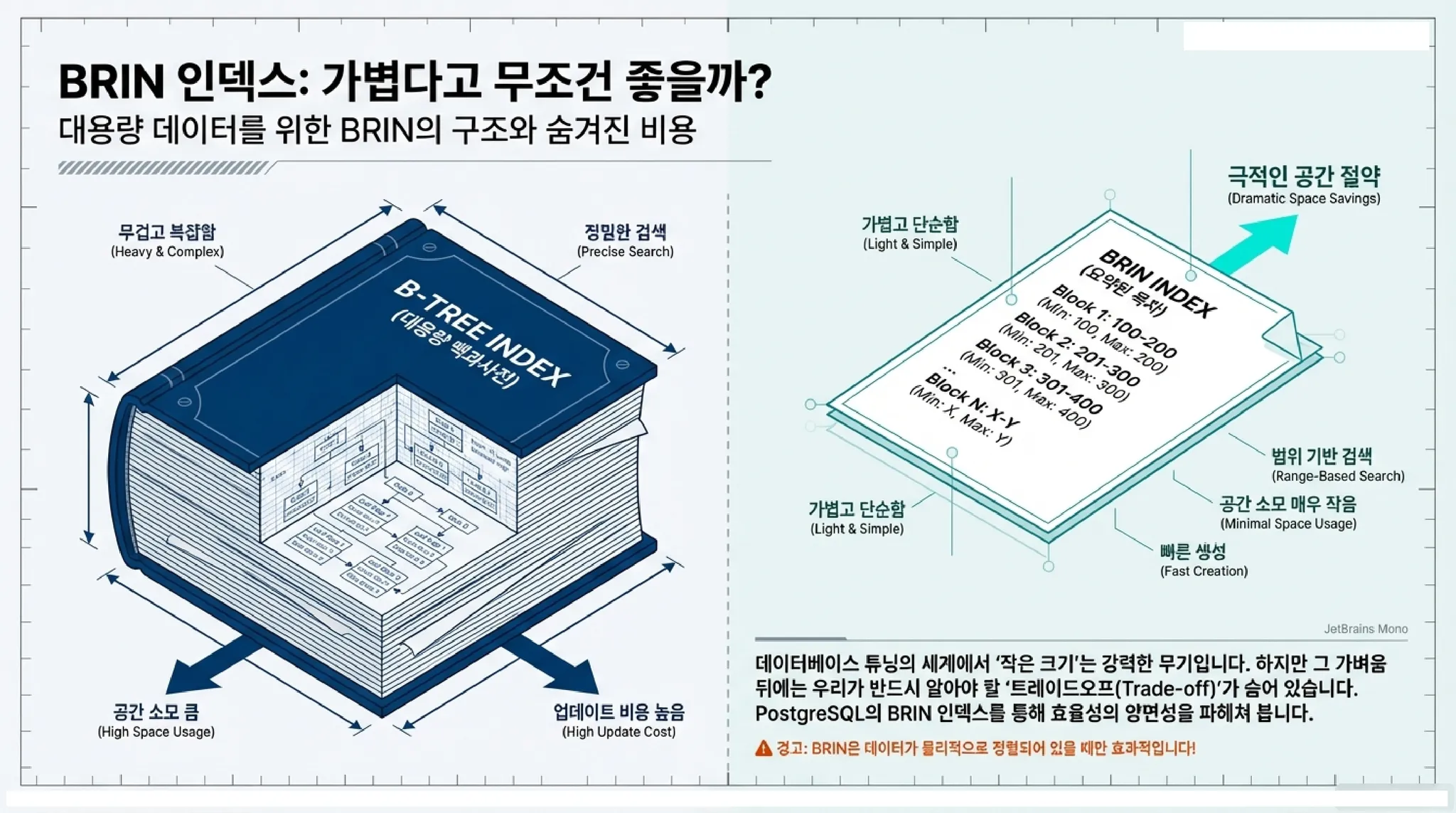
여기서는 책에서 다루지 않았던 BRIN 인덱스에 추가 설명을 해보고자 한다.
BRIN(Block Range Index)은 모든 데이터를 일일이 기록하는 대신 기본적으로 데이터 블록의 범위별 최솟값과 최댓값만을 요약하여 저장하는 효율적인 데이터베이스 색인 방식이다. 실제 BRIN이 얼마나 효과가 있는지 연구해 보자.
B+ 트리 인덱스로 단 건 조회
먼저 B+ 트리로 구성된 pk(ord_no) 인덱스로 한 건의 데이터를 조회해보자. 아래와 같다.
•
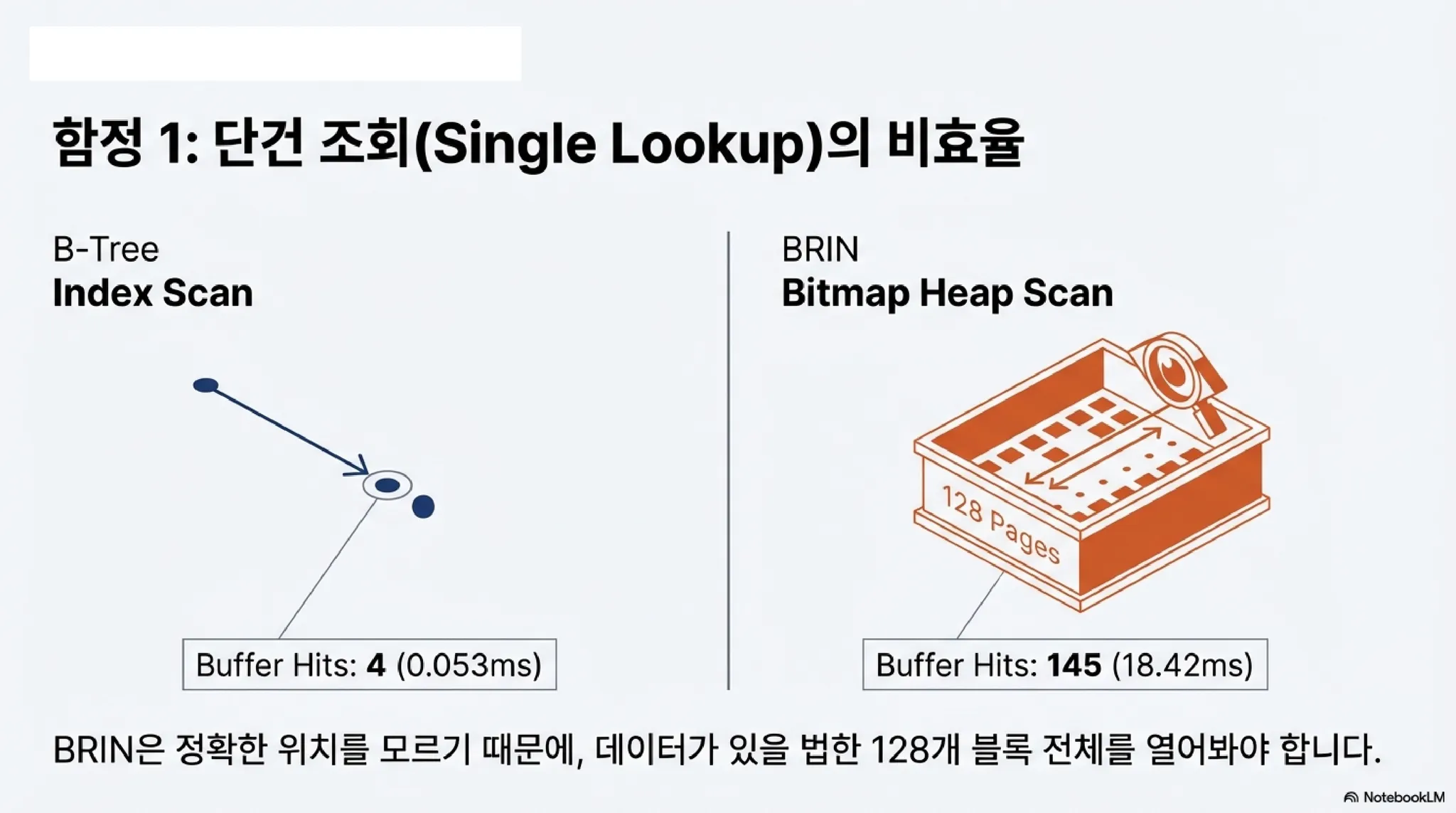
Buffers: hit 4 / 실행시간: 0.053ms
EXPLAIN (ANALYZE,BUFFERS,COSTS OFF)
SELECT t1.*
FROM startdbpg.tr_ord_big t1
WHERE t1.ord_no = 100;
Index Scan using tr_ord_big_pk on tr_ord_big t1 (actual time=0.030..0.032 rows=1 loops=1)
Index Cond: (ord_no = '100'::numeric)
Buffers: shared hit=4
Planning Time: 0.105 ms
Execution Time: 0.053 ms
SQL
복사
BRIN으로 단 건 조회
위와 동일한 SQL을 BRIN을 생성해 처리해보자. 아래와 같다. 새로 만든 BRIN을 사용하도록 힌트를 적용해야 한다.
•
Buffers: hit 145 / 실행시간: 18.420ms
•
BRIN은 IndexScan 방식의 데이터 검색이 불가능하다. BitmapScan으로만 데이터를 검색할 수 있다.
◦
결과적으로 한 건의 데이터를 찾는데도 Bitmap을 만드는 부하가 추가된다.
◦
BitmapScan만 가능하므로 IndexScan 힌트를 주어도 BitmapScan으로 작동한다.
•
더 심각한 것은 한 건의 레코드를 찾는데 무려 145개의 블록을 읽었다는 점이다.
◦
BRIN은 기본적으로 128개의 블록을 '한 묶음'으로 관리하기 때문에, 단 1건을 찾더라도 그 묶음 전체(128개)를 필수적으로 다 읽어야 하기 때문이다.
CREATE INDEX tr_ord_big_brin_ord_no ON startdbpg.tr_ord_big USING BRIN(ord_no);
EXPLAIN (ANALYZE,BUFFERS,COSTS OFF)
/*+ BitmapScan(t1 tr_ord_big_brin_ord_no) */
SELECT t1.*
FROM startdbpg.tr_ord_big t1
WHERE t1.ord_no = 100;
Bitmap Heap Scan on tr_ord_big t1 (actual time=17.197..18.120 rows=1 loops=1)
Recheck Cond: (ord_no = '100'::numeric)
Rows Removed by Index Recheck: 9599
Heap Blocks: lossy=128
Buffers: shared hit=145
-> Bitmap Index Scan on tr_ord_big_brin_ord_no (actual time=1.140..1.141 rows=1280 loops=1)
Index Cond: (ord_no = '100'::numeric)
Buffers: shared hit=17
Planning:
Buffers: shared hit=2
Planning Time: 0.149 ms
Execution Time: 18.420 ms
SQL
복사
B+ 트리 인덱스로 3백만 건 조회
3백만 건의 데이터를 B+ 트리 인덱스로 조회
•
Buffers: read 48200 / 실행시간: 995.378ms
EXPLAIN (ANALYZE,BUFFERS,COSTS OFF)
SELECT t1.*
FROM startdbpg.tr_ord_big t1
WHERE t1.ord_no BETWEEN 1000000 AND 4000000;
Index Scan using tr_ord_big_pk on tr_ord_big t1 (actual time=0.212..841.704 rows=3000001 loops=1)
Index Cond: ((ord_no >= '1000000'::numeric) AND (ord_no <= '4000000'::numeric))
Buffers: shared read=48200
Planning:
Buffers: shared read=1
Planning Time: 1.350 ms
Execution Time: 995.378 ms
SQL
복사
BRIN으로 3백만 건 조회
3백만 건의 데이터를 BRIN으로 조회
•
Buffers: hit=5 read=40076 / 실행시간: 573.970ms
EXPLAIN (ANALYZE,BUFFERS,COSTS OFF)
/*+ BitmapScan(t1 tr_ord_big_brin_ord_no) */
SELECT t1.*
FROM startdbpg.tr_ord_big t1
WHERE t1.ord_no BETWEEN 1000000 AND 4000000;
Bitmap Heap Scan on tr_ord_big t1 (actual time=24.799..474.283 rows=3000001 loops=1)
Recheck Cond: ((ord_no >= '1000000'::numeric) AND (ord_no <= '4000000'::numeric))
Rows Removed by Index Recheck: 4799
Heap Blocks: lossy=40064
Buffers: shared hit=5 read=40076
-> Bitmap Index Scan on tr_ord_big_brin_ord_no (actual time=2.287..2.288 rows=400640 loops=1)
Index Cond: ((ord_no >= '1000000'::numeric) AND (ord_no <= '4000000'::numeric))
Buffers: shared hit=5 read=12
Planning:
Buffers: shared hit=2
Planning Time: 0.158 ms
Execution Time: 573.970 ms
SQL
복사
B+ 트리 vs BRIN
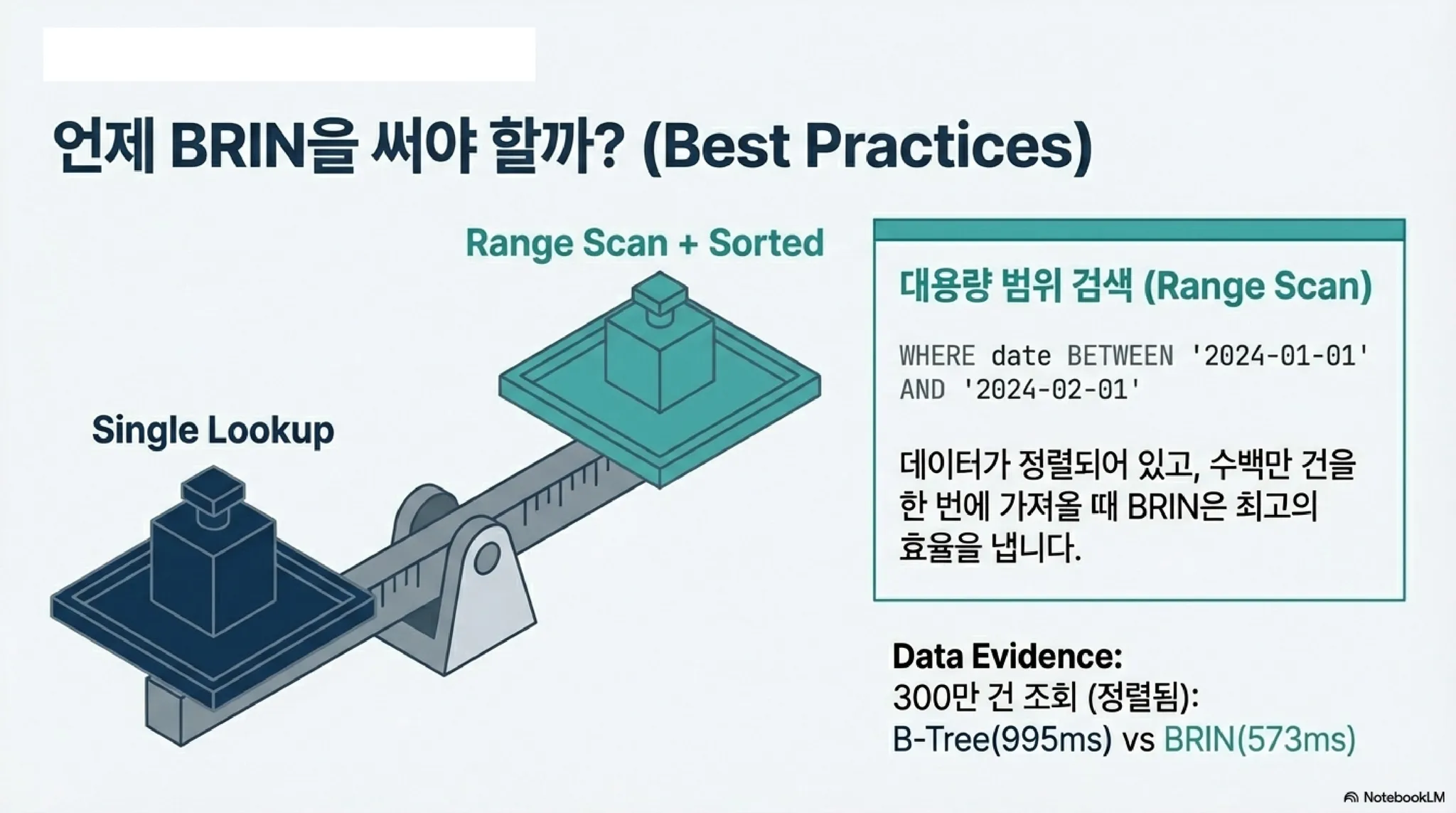
지금까지 내용을 정리해보면 아래와 같다. 결과적으로 단 건을 조회한다면 BRIN은 매우 비효율적이다. 반면에 많은 건수를 조회할수록 BRIN이 좀 더 좋을 수 있다.
단 건 조회 | 3백만 건 조회 | |
B+ 트리 | hit=4 | read=48200 |
BRIN | hit=145 | hit=5 read=40076 |
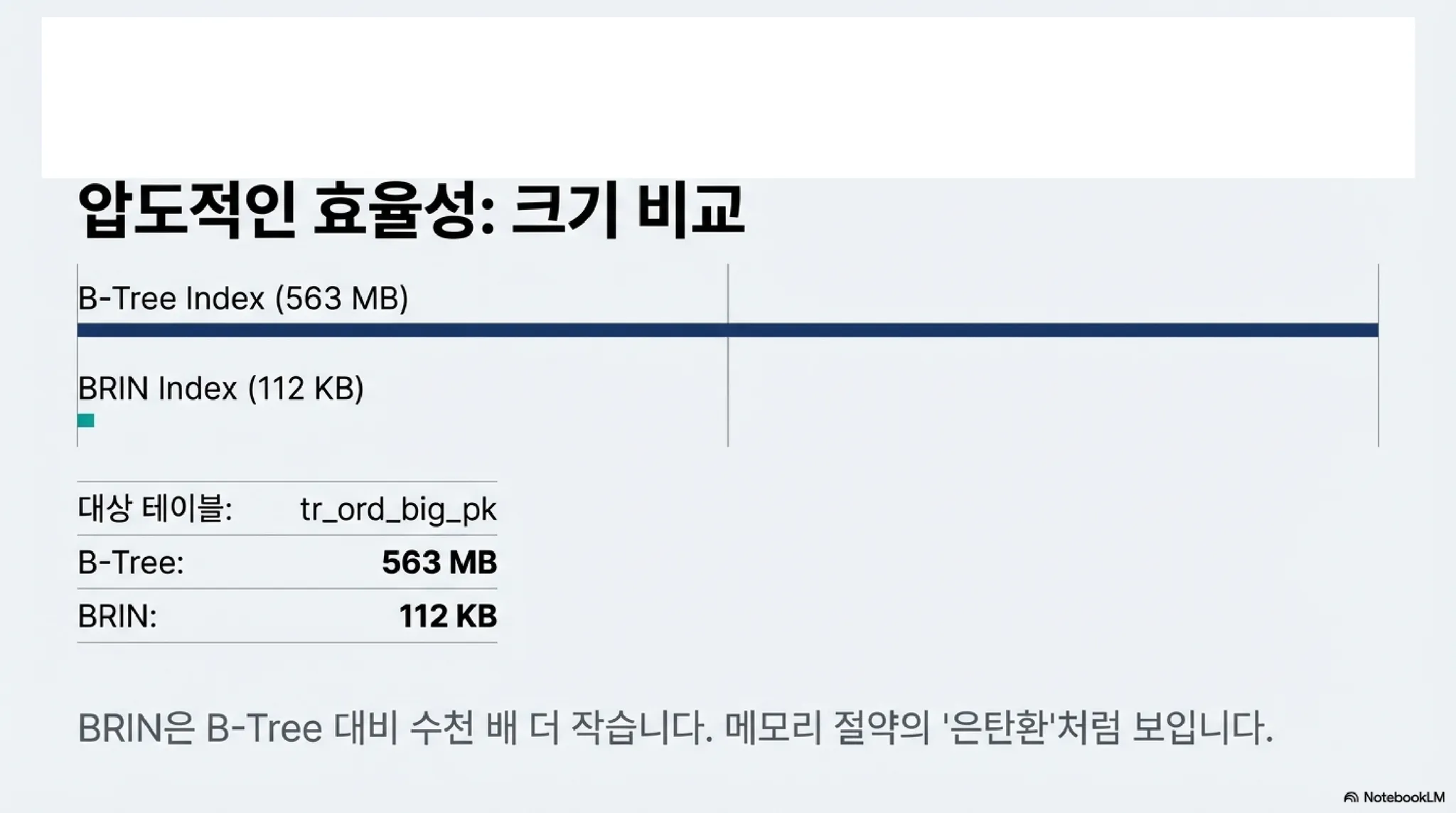
BRIN의 최대 강점 중 하나는 인덱스 크기가 매우 작다는 것이다. 아래 SQL로 인덱스 크기를 비교해보자. 같은 ord_no에 대한 인덱스이지만 크기가 112kb(BRIN) vs. 563MB(B+트리)로 매우 크게 차이 나는 것을 알 수 있다.
SELECT t1.indexname
,pg_size_pretty(pg_relation_size((t1.schemaname || '.' || t1.indexname)::regclass)) ix_size
,t1.indexdef
FROM pg_indexes t1
WHERE t1.indexname IN ('tr_ord_big_brin_ord_no','tr_ord_big_pk')
ORDER BY t1.indexname;
indexname |ix_size|indexdef |
----------------------+-------+-------------------------------------------------------------------------------+
tr_ord_big_brin_ord_no|112 kB |CREATE INDEX tr_ord_big_brin_ord_no ON startdbpg.tr_ord_big USING brin (ord_no)|
tr_ord_big_pk |563 MB |CREATE UNIQUE INDEX tr_ord_big_pk ON startdbpg.tr_ord_big USING btree (ord_no) |
SQL
복사
많은 데이터를 조회하면 항상 BRIN?
위 결과로 BRIN으로 많은 데이터를 조회하면 성능에 유리하다고 단정해서는 안된다. BRIN은 테이블에 저장된 물리적인 데이터 순서가 BRIN으로 구성한 컬럼 순서와 일치 할 경우에만 성능에 도움이 된다.
지금까지 테스트한 tr_ord_big 테이블은 ord_no 순서로 데이터가 저장되어 있다. 그러므로 ord_no로 구성된 BRIN으로 많은 데이터를 조회하기에는 유리한 구성이었다. 아래와 같이 shop_id로 B+ 트리 인덱스와 BRIN을 구성하고 테스트해보자.
•
shop_id는 tr_ord_big 테이블과 저장 순서가 일치하지 않는다.
◦
관련해서는 SQL TUNER for PostgreSQL의 ‘5-4-3. CLUSTER’ 절에서 설명한다.
CREATE INDEX tr_ord_big_btree_shop ON startdbpg.tr_ord_big(shop_id);
CREATE INDEX tr_ord_big_brin_shop ON startdbpg.tr_ord_big USING BRIN(shop_id);
EXPLAIN (ANALYZE,BUFFERS,COSTS OFF)
/*+ IndexScan(t1 tr_ord_big_btree_shop) */
SELECT t1.*
FROM startdbpg.tr_ord_big t1
WHERE t1.shop_id = 'S100';
Index Scan using tr_ord_big_btree_shop on tr_ord_big t1 (actual time=0.060..1241.924 rows=3055860 loops=1)
Index Cond: ((shop_id)::text = 'S100'::text)
Buffers: shared read=233496
Planning:
Buffers: shared read=1
Planning Time: 0.273 ms
Execution Time: 1432.328 ms
EXPLAIN (ANALYZE,BUFFERS,COSTS OFF)
/*+ BitmapScan(t1 tr_ord_big_brin_shop) */
SELECT t1.*
FROM startdbpg.tr_ord_big t1
WHERE t1.shop_id = 'S100';
Bitmap Heap Scan on tr_ord_big t1 (actual time=58.569..2801.389 rows=3055860 loops=1)
Recheck Cond: ((shop_id)::text = 'S100'::text)
Rows Removed by Index Recheck: 22314312
Heap Blocks: lossy=338269
Buffers: shared hit=5 read=338281
-> Bitmap Index Scan on tr_ord_big_brin_shop (actual time=20.160..20.161 rows=3382690 loops=1)
Index Cond: ((shop_id)::text = 'S100'::text)
Buffers: shared hit=5 read=12
Planning:
Buffers: shared hit=5
Planning Time: 0.185 ms
Execution Time: 2911.702 ms
SQL
복사
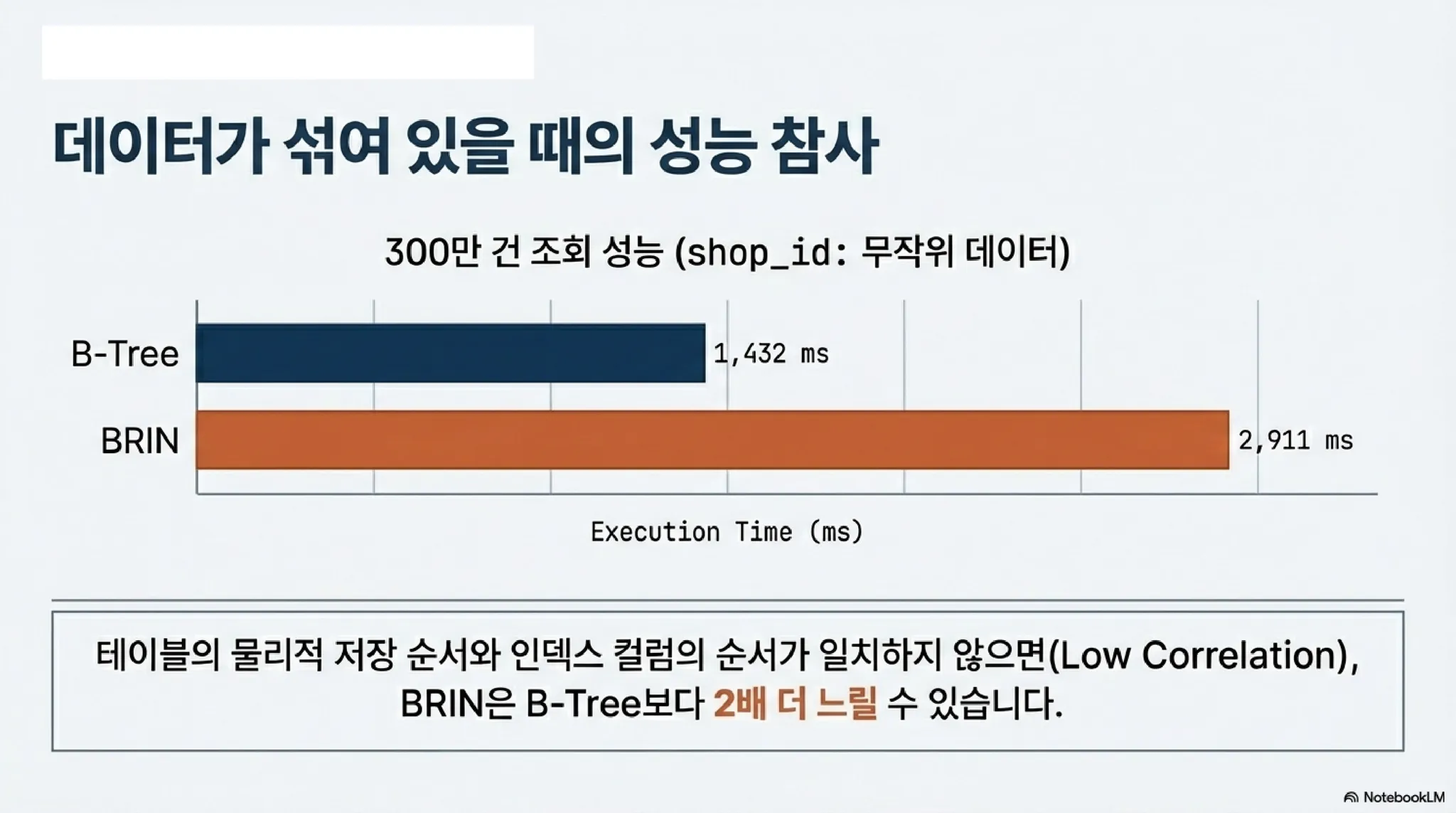
동일한 조건으로 약 3백만건을 조회하는데 다음과 같이 성능 차이가 있다.
•
B+ 트리 인덱스(shop_id)
◦
Buffers: read 233496 / 실행시간: 1432.328ms
•
BRIN(shop_id)
◦
Buffers: hit=5 read 338281/ 실행시간: 2911.702ms
테이블의 물리적인 순서와 인덱스 컬럼의 순서가 일치하지 않으면 많은 데이터를 조회하는데 BRIN 인덱스가 더 좋지 않은 것을 알 수 있다. 결국, 테이블의 데이터 저장 순서가 보장되지 않는 힙 구조의 테이블에서 BRIN은 심각하게 고민하고 도입할 필요가 있다. 분명히 성능상 이점이 되는 부분이 존재하지만, 반대로 이슈가 되는 부분도 분명히 존재하기 때문이다.
아래 상황도 추가로 살펴보자. 약 3만 건의 데이터를 조회하면서 shop_id로 구성된 BRIN 인덱스를 사용하면 B+ 트리 인덱스보다 성능이 매우 좋지 못한 것을 알 수 있다.
EXPLAIN (ANALYZE,BUFFERS,COSTS OFF)
/*+ IndexScan(t1 tr_ord_big_btree_shop) */
SELECT t1.*
FROM startdbpg.tr_ord_big t1
WHERE t1.shop_id = 'S256';
Index Scan using tr_ord_big_btree_shop on tr_ord_big t1 (actual time=0.283..96.406 rows=29160 loops=1)
Index Cond: ((shop_id)::text = 'S256'::text)
Buffers: shared read=27625
Planning:
Buffers: shared hit=1
Planning Time: 0.376 ms
Execution Time: 98.794 ms
EXPLAIN (ANALYZE,BUFFERS,COSTS OFF)
/*+ BitmapScan(t1 tr_ord_big_brin_shop) */
SELECT t1.*
FROM startdbpg.tr_ord_big t1
WHERE t1.shop_id = 'S256';
Bitmap Heap Scan on tr_ord_big t1 (actual time=76.562..2447.136 rows=29160 loops=1)
Recheck Cond: ((shop_id)::text = 'S256'::text)
Rows Removed by Index Recheck: 21894612
Heap Blocks: lossy=292317
Buffers: shared hit=5 read=292329
-> Bitmap Index Scan on tr_ord_big_brin_shop (actual time=21.992..21.993 rows=2923170 loops=1)
Index Cond: ((shop_id)::text = 'S256'::text)
Buffers: shared hit=5 read=12
Planning:
Buffers: shared hit=2
Planning Time: 0.221 ms
Execution Time: 2449.747 ms
SQL
복사
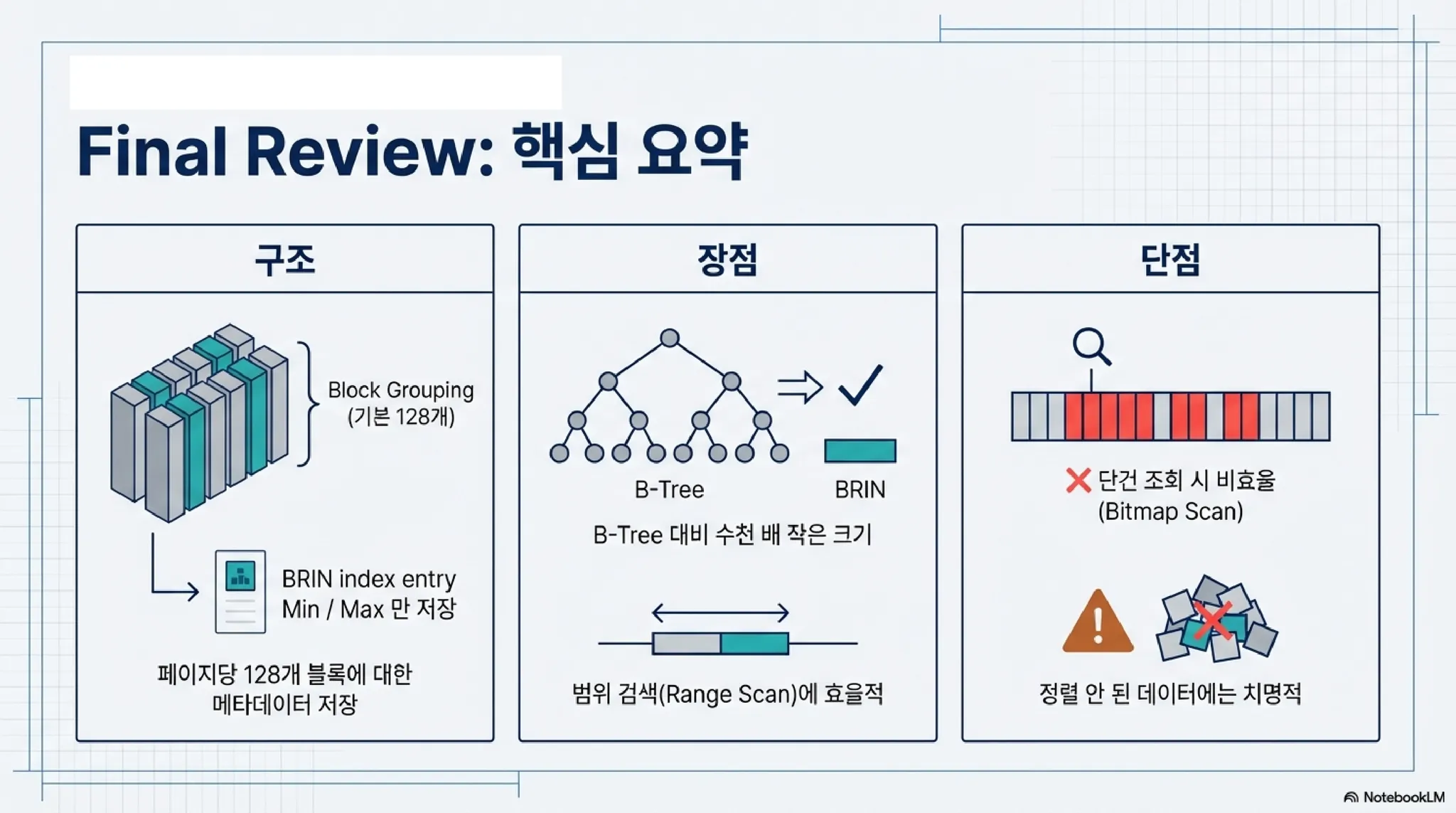
BRIN은 어떤 구조인가?
앞선 실험에서 우리는 두 가지 의문을 가질 수 있다.
1.
왜 인덱스 크기가 B+ 트리에 비해 압도적으로 작은가? (563MB vs 112KB)
2.
왜 단 한 건을 찾는데도 128개 이상의 블록을 읽어야 하는가?
이 의문을 풀기 위해서는 BRIN(Block Range Index)의 내부 구조를 들여다봐야 한다. 이름에서 알 수 있듯이, BRIN은 개별 데이터 행(Row)을 가리키는 것이 아니라 블록의 범위(Block Range)를 관리합니다. <여기서 주의할 점은 ‘블록의 범위’가 하나의 블록에 저장된 값의 범위가 아니라, 여러 블록을 결합한 범위란 점이다>
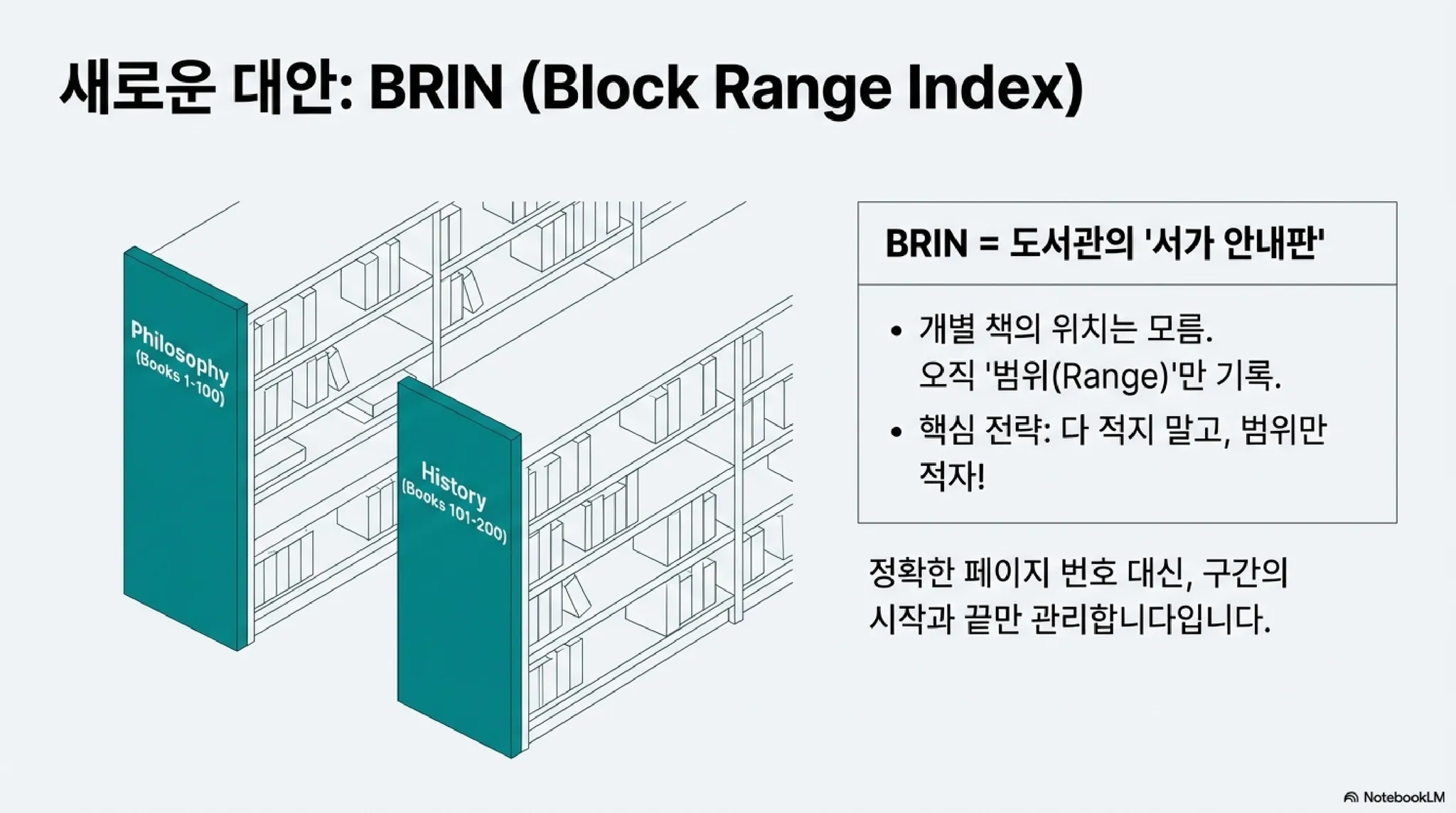
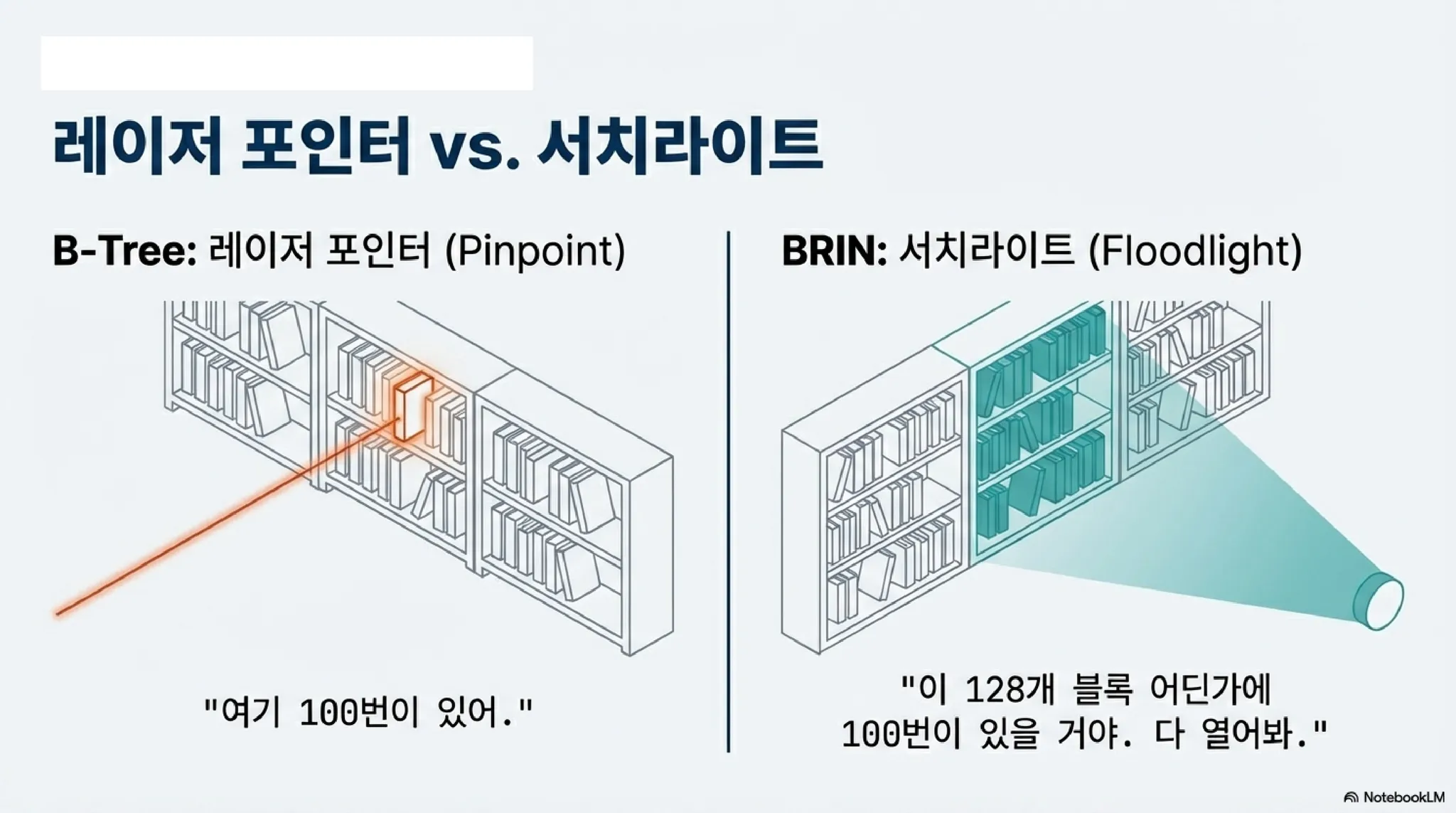
1. 책의 쪽수 vs. 도서관의 서가 안내판
이해하기 쉽게 비유를 들어보자.
•
B+ 트리 인덱스는 전공 서적 맨 뒤에 있는 '색인(Index)'과 같다. "단어 A는 153페이지 5번째 줄에 있다"라고 정확한 위치를 알려준다. 그래서 빠르지만, 모든 단어의 위치를 기록해야 하므로 색인의 양이 많다.
•
BRIN은 도서관 입구에 있는 '서가 안내판'과 같다. ‘철학 책은 1번~10번 책장에 있다’ 정도만 알려준다. 정확히 몇 번째 책장, 몇 번째 칸에 있는지는 알려주지 않지만, 안내판의 크기는 매우 작다.
2. 블록(페이지) 묶음과 요약 정보 (Min/Max)
PostgreSQL은 데이터를 블록 단위로 저장한다. BRIN은 이 블록들을 일정 개수(기본 128개)로 묶어 하나의 '범위(Range)'로 정의한다. 그리고 BRIN에는 그 128개 페이지 안에 들어있는 데이터 중 최솟값(Min)과 최댓값(Max)만 딱 기록해 둔다.
BRIN의 핵심 구조:
•
Range 1 (페이지 0~127): 최솟값 1, 최댓값 10,000
•
Range 2 (페이지 128~255): 최솟값 10,001, 최댓값 20,000
이 구조 때문에 앞선 실험에서 인덱스 크기가 112KB밖에 되지 않았던 것이다. 수백만 건의 데이터 위치를 일일이 저장하는 대신, 128개 블록당 딱 1개의 요약 정보만 저장했기 때문이다. 결과적으로 BRIN을 활용하면 단 건 조회시에도 한 묶음인 최소 128개 블록을 살펴봐야만 한다.
앞의 실험에서 WHERE ord_no = 100을 조회했을 때 BRIN은 다음과 같이 작동한다.
1.
BRIN 인덱스를 봅니다.
2.
"Range 1의 범위가 1~10,000이니까, 100은 Range 1 어딘가에 있겠군." 이라고 판단합니다.
3.
하지만 정확히 몇 번째 블록에 있는지는 모릅니다.
4.
결국 Range 1에 속한 128개의 페이지를 전부 다 읽어서(Bitmap Heap Scan) 100을 찾습니다.
이것이 바로 앞에서 Buffers: shared hit=145가 나온 이유다. (인덱스 자체를 읽는 버퍼 + 데이터 블록 128개 묶음 + 메타데이터 등). BRIN은 위치를 '정확히' 찍어주는 것이 아니라 '후보군'만 던져주는 인덱스다.
추가로, BRIN을 생성할 때 블록 묶음 갯수를 지정할 수 있으며 128이 기본으로 설정되어 있다. 이 묶음 수를 작게 작으면 소량 데이터 조회에 조금 더 유리해질 가능성이 있다.
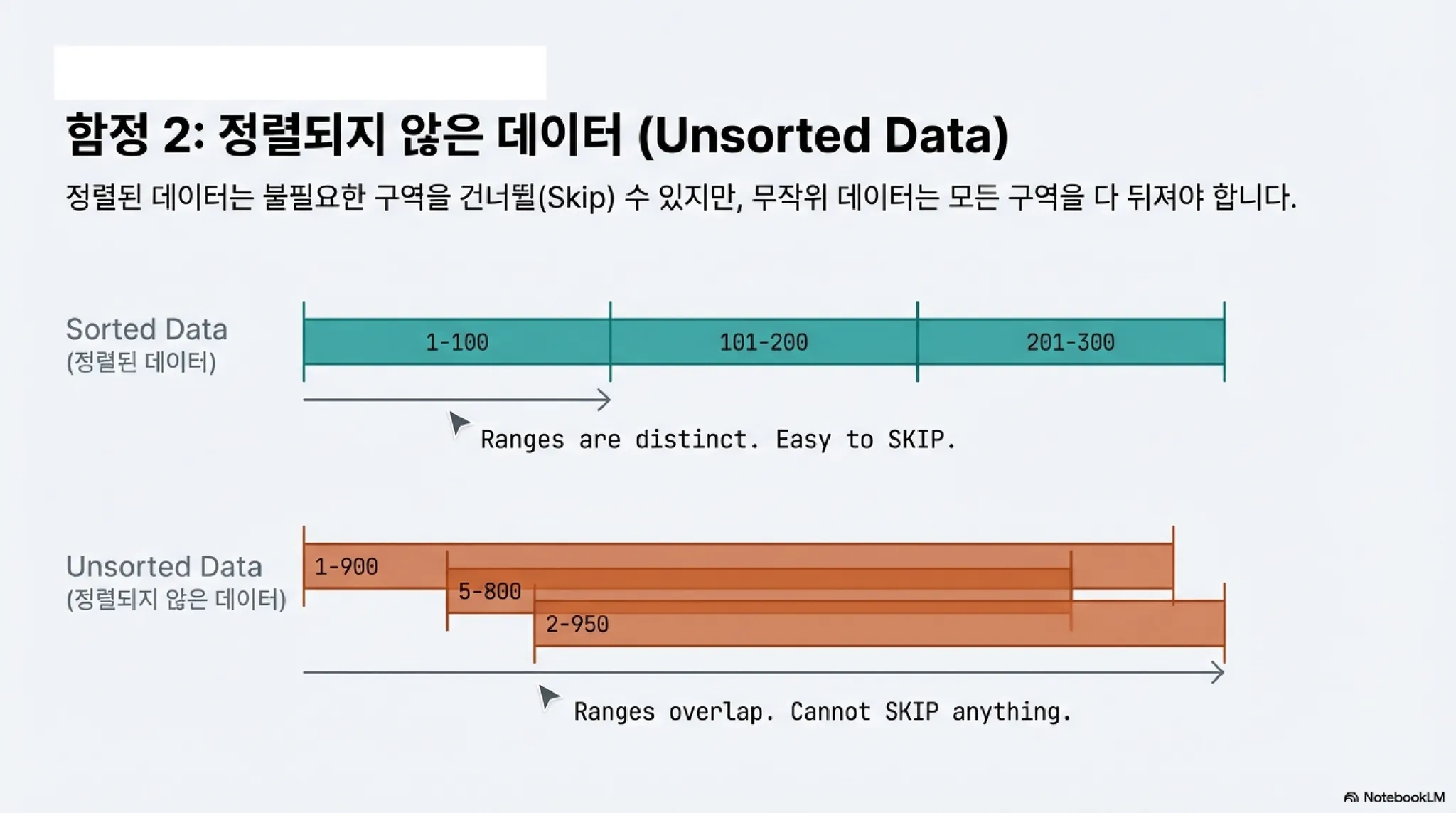
3. 데이터 정렬이 성능을 좌우하는 이유 (Correlation)
마지막으로 shop_id 실험에서 성능이 떨어졌던 이유를 구조적으로 보면 다음과 같다.
•
정렬된 데이터 (ord_no):
◦
Range A: 1~100 (깔끔함)
◦
Range B: 101~200 (깔끔함)
◦
검색 시 Range A만 뒤지고 Range B는 쳐다볼 필요도 없다.
•
정렬되지 않은 데이터 (shop_id):
◦
Range A: S001 ~ S999 (S100이 여기 있을 수 있음)
◦
Range B: S005 ~ S990 (S100이 여기도 있을 수 있음)
◦
데이터가 뒤죽박죽 섞여 있으면, 모든 Range의 Min/Max 범위가 넓어지고 서로 겹치게 된다.
◦
결국 BRIN 인덱스를 봐도 ‘S100은 모든 Range에 있을 가능성이 있다’는 결론이 나와, 사실상 많은 데이터를 뒤지게 될 수 있다.
결론: BRIN은 '무엇을 건너뛸지' 알려주는 인덱스
BRIN의 구조를 한마디로 요약하면 ‘여기는 확실히 없다’를 알려주기 위한 인덱스이다
끝으로 테스트 과정에서 만든 인덱스를 삭제하도록 하자
DROP INDEX tr_ord_big_brin_ord_no;
DROP INDEX tr_ord_big_brin_shop;
DROP INDEX tr_ord_big_btree_shop;
SQL
복사
노트북LM의 영상 요약과 슬라이드 요약
위 설명과 같이 보면 도움이 될거 같네요.