



관계형 데이터 모델
우리가 SQL로 다루는 데이터는 관계형 데이터다. 여기서 관계(Relation)란 데이터를 행(Row)과 열(Column)로 조직화한 구조를 의미한다. 즉, 테이블이다. 테이블은 관계형 데이터 모델 개념으로 설계된다. 관계형 데이터 모델 이론은 데이터 활용에 있어 중요한 요소다. SQL로 데이터를 활용할 수 있지만, 그 전에 제대로 된 테이블 구조에 데이터가 저장되어 있어야 한다. 테이블 구조에 따라 SQL 작성 방법이 달라진다. 테이블 구조에 문제가 있으면 정확한 데이터 추출이 불가능할 수도 있다. 필요 이상으로 테이블이 복잡하게 설계되었다면 SQL 작성도 매우 복잡해질 수 있다. SQL에 대한 공부가 어느 정도 마무리되었다면, 관계형 데이터 모델 공부에 시간을 투자해보기 바란다. 제대로 데이터를 쌓아야, 제대로 데이터를 활용할 수 있다. SQL만 공부한 사람과 SQL과 데이터 모델링을 모두 공부한 사람 간의 데이터 활용 능력은 시간이 갈수록 큰 차이가 날 수 있다.
관계형 데이터 모델링 관련해서는 서점에 가서 본인에게 잘 읽히는 책을 직접 찾는 것을 권장한다. 가능하면 쉬운 용어로 이해가 어렵지 않은 내용의 책으로 시작하는 것을 추천한다.
테이블 설계 과정
테이블 설계 과정을 아주 간단하게 살펴보고 넘어가도록 하자. 관계형 데이터 모델은 개념 설계, 논리 설계, 물리 설계의 세 단계로 이루어진다.
•
개념 설계: 관리할 데이터의 핵심적인 개념만 정리해서 표현
◦
주로 엔티티명(논리 테이블명)과 식별자 정도를 정의
•
논리 설계: 개념 설계를 좀 더 상세화하는 단계
◦
엔티티(논리 테이블명)에 필요한 모든 속성(컬럼의 논리명)을 도출
•
물리 설계: 논리 설계의 결과를 실제 구현할 DBMS에 맞게 설계하는 과정
최근에는 실제 프로젝트에서 논리 설계와 물리 설계를 정확히 분리해서 진행하는 경우는 드물다. 다양한 이유로 논리 설계와 물리 설계가 동시에 이루어지는 경우가 많다. 프로세스상 나누어 놓아도 실제로는 거의 동시에 이루어지기도 한다. 논리 설계와 물리 설계를 동시에 진행하는 방법론이 맞다, 틀리다로 잘라 말하기는 어렵다. 중요한 것은 정해진 자원과 시간내에서 최대의 효율적인 방법을 찾아야 하며, 이후에도 이 모델이 잘 사용되도록 고민하는 것이다.
관계 데이터를 설계하는 과정에서 중요한 개념 중 하나로 정규화(Normaliztion)가 있다. 개념 설계부터 물리 설계까지 항상 정규화를 유념해서 설계를 진행하게 된다. 여기서 정규화까지 설명할 수는 없다. 매우 중요한 내용이지만, 간단하게 설명할 수 있는 부분이 아니기 때문이다.
관계형 데이터 모델 기법을 이용해 테이블을 설계할 때는 ERD(Entity-Relation-Diagram) 툴을 사용한다. 대표적인 툴로 ERWIN이 있으며, 우리나라에서는 DA#도 많이 사용된다. 안타깝게도 유료툴이다. 개인 연습용으로 ERD를 그려보고 싶다면 ERD-CLOUD와 같은 웹상의 무료 플랫폼도 있으니 참고하기 바란다.
설계와 실제 테이블
ERD 툴로 설계된 상품 테이블과 실제 저장된 상품 데이터를 비교해보면 아래와 같다.
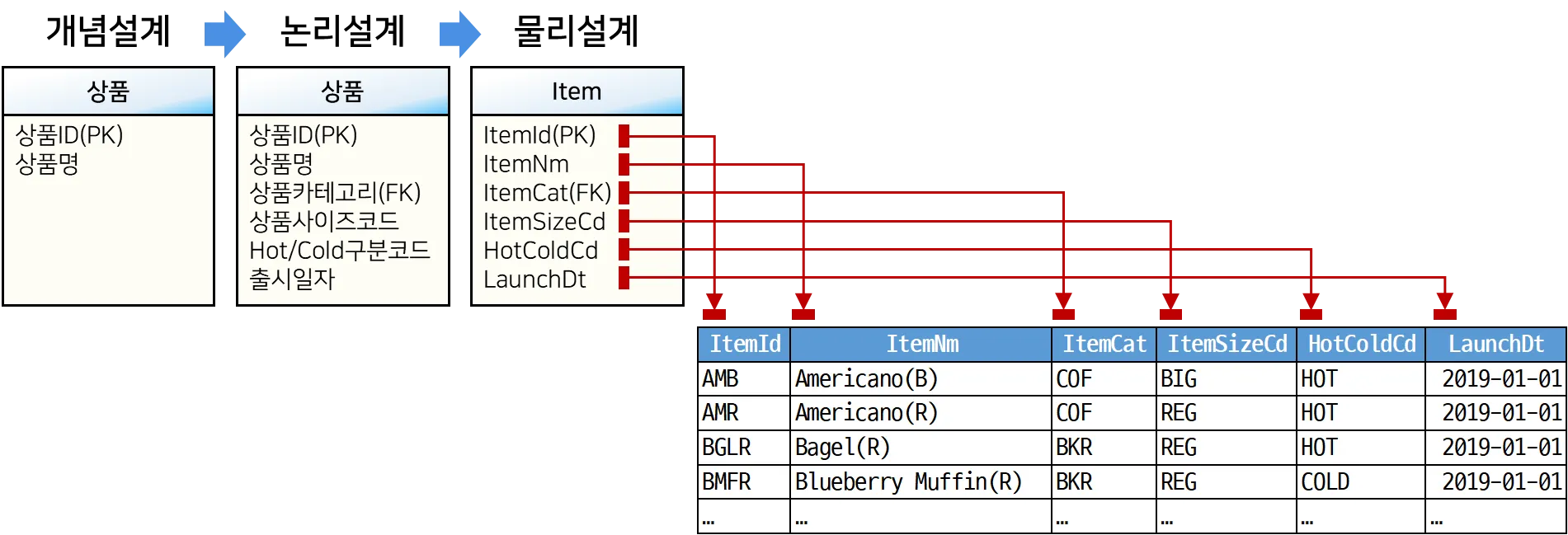
테이블에서 데이터를 조회하면 위 그림의 오른쪽과 같이 컬럼이 가로로 펼쳐지고 저장된 값들이 위에서 아래로 출력된다. 그런데, ERD Tool로 테이블을 설계할 때는 그림 왼쪽과 같이 컬럼을 위에서 아래로 채워가면서 세로로 표시한다. 이처럼 컬럼을 세로로 나열해야 더 많은 테이블을 효율적으로 설계할 수 있다.
UNIQUE KEY
테이블 설계 과정에서 가장 중요한 것 하나를 뽑으라면 바로 PK(Primary Key)다. PK를 이해하려면 UK(UNIQUE KEY)에 대해 먼저 알아야 한다. UK는 데이터 집합에서 레코드를 유일하게 식별할 수 있는 속성(컬럼)의 집합을 뜻한다. 데이터를 유일하게 식별할 수 있다는 것은, 데이터 집합에서 한 건의 레코드만 정확히 골라낼 수 있다는 뜻이다.
A 대학교에 재학 중인 학생 데이터 집합의 UK로 학번을 사용할 수 있다. 한 학교에서 학번은 중복되지 않는다. 9627015란 학번을 가진 학생이 두 명 이상 존재할 수 없다. 그러므로 학번을 이용하면 정확히 한 명의 학생만 찾아낼 수 있다. 이처럼 데이터 집합에서 한 건만 정확히 골라낼 수 있는 속성을 UK라고 한다.
코인 노래방에서 원하는 노래를 정확히 선택해서 부르려면 노래 번호를 선택해야 한다. 노래 번호가 노래방의 노래를 식별하는 UK다. 비싼 가전제품을 구매해보면 시리얼번호가 부여되어 있다. 이 시리얼 번호 역시 특정 가전제품군의 상품을 하나하나 구별하는 UK다.
하나의 데이터 집합은 여러 개의 UK를 가질 수 있다. 다시 학생 데이터 집합으로 돌아가보자. 학번 외에도 주민등록번호, 이메일, 핸드폰 번호도 UK로 사용할 수 있다. 또한 UK는 여러 속성을 결합해 사용할 수도 있다. 학생이 수업을 신청한 "수강신청"이라는 데이터 집합은 "학번, 과목, 학기"(예: 2023년 1학기, 2023년 2학기) 세 개의 속성을 결합해 UK로 사용할 수 있다.
UK에 대해 정리해보면 아래와 같다.
•
UK는 데이터 집합(테이블)에서 데이터 한 건을 유일하게 식별해 낼 수 있는 속성
•
하나의 데이터 집합에 여러 개의 UK가 있을 수 있다.
•
하나의 UK는 여러 속성(컬럼)을 결합해 사용할 수 있다.
PRIMARY KEY
UK를 설명한 이유는 PK(Primary Key)를 설명하기 위함이다. 그런데 UK를 이해했다면 PK를 이해하기 크게 어렵지 않다. PK는 데이터 집합의 UK 중에서 대표로 사용하는 UK이기 때문이다. 예를 들어, 학생의 UK로 학번, 주민등록번호, 이메일, 핸드폰번호가 있는데, 이 중에 하나를 Primary Key로 정한다. PK 외에 나머지 UK는 대체키(Alternate Key)가 된다.
PK 설정을 위한 간단한 규칙이 있다.
•
테이블에 하나의 PK만 설정할 수 있다.
•
PK는 데이터를 식별해야 한다.
•
NULL 값을 포함할 수 없다.
•
보안이 필요한 속성은 사용할 수 없다.
•
변경이 발생하는 속성은 사용할 수 없다.
◦
상황에 따라 사용 할 수도 있지만 가능하면 피하는 것이 좋다.
•
가능하면 짧아야 한다.
앞에서 "테이블 설계 과정에서 가장 중요한 것 하나를 뽑으라면 바로 PK(Primary Key)다."라고 언급했다. 데이터를 활용하려면 데이터의 정확성이 뒷받침되어야 한다. 데이터 정확성을 위해서는 중복된 데이터가 있어서는 안된다. 이를 보장하기 위해 필요한 최소한의 장치가 바로 PK다. 또한 데이터를 보다 다채롭게 활용하기 위해서 데이터와 데이터를 연결(조인)해야 하는데, 데이터 연결을 위해 사용하는 컬럼도 바로, PK와 PK를 참조하는 FK(Foreign Key/외래키) 컬럼이다. (FK에 대해서는 뒤에서 설명한다.) 혹시라도 PK가 “바지 사장”처럼 하는 일 없이 겉으로만 존재한다면 PK를 잘 못 선정한 걸 수도 있다. PK 컬럼은 많은 일을 한다. 조인 조건으로 자주 사용되며 데이터 조회 조건으로도 빈번히 사용된다. 우리가 선정한 PK가 역할 없는 “바지 사장”이 아닌지 고민해볼 필요가 있다.
테이블에는 PK 컬럼과 PK가 아닌 컬럼이 있다. 이 두 집단에는 종속 관계가 있다. 종속이란 자주이 없이 주가 되는 것에 딸려 붙은 상태다. PK 컬럼이 주가 되고 PK가 아닌 컬럼은 PK에 딸려 붙은 속성이다. PK가 아닌 컬럼은 PK에 종속적이라는 뜻이다. 아래 SQL과 결과를 살펴보자.
-- [SQL-4-1-1] Item 테이블 살펴보기, PK가 아닌 컬럼은 PK 컬럼에 종속적이다.
SELECT T1.*
FROM startdb.Item T1
ORDER BY T1.ItemID
LIMIT 5;
ItemId ItemNm ItemCat ItemSizeCd HotColdCd LaunchDt
------ ------------------- ------- ---------- --------- ----------
AMB Americano(B) COF BIG HOT 2019-01-01
AMR Americano(R) COF REG HOT 2019-01-01
BGLR Bagel(R) BKR REG HOT 2019-01-01
BMFR Blueberry Muffin(R) BKR REG COLD 2019-01-01
CITR Yuzu Ade(R) BEV REG COLD 2023-04-01
SQL
복사
Item 테이블의 PK는 ItemId다. 그러므로 ItemId를 제외한 나머지 컬럼은 ItemId에 종속적이다. ItemId가 AMB라면, 반드시 ItemNm은 Americano(B)다. ItemCat는 COF이고 ItemSizeCd는 BIG이다. HotColdCd는 HOT이며, Launchdt는 2019년 1월 1일이다. 누군가 데이터를 변경하기 전까지는 이러한 종속 관계가 유지된다.
PK는 데이터의 정확성과 활용에 많은 영향을 준다. 그리고 나머지 값들은 PK에 종속된다. PK를 정하기 위해 고민과 고민을 거듭해야 한다. 이러한 고민의 시간은 자신의 성장에 큰 도움이 될 것이며, PK 선정을 위해 고심한 시간은 데이터 모델의 완성도를 높여주며, 개발 편의성에도 도움을 주게 될 것이다.
