본 글은 데이터 분석 방법론을 설명하기 위해 작성되었으며, 어떠한 형태로도 투자 권유를 목적으로 하지 않습니다. 제공된 분석 기술은 수익을 보장하지 않으며, 본 글에 언급된 어떠한 종목도 투자를 권유하는 것이 아님을 명시합니다. 분석 내용의 적용으로 인한 모든 결과에 대한 책임은 독자 본인에게 있습니다.
•
오늘 수행하는 분석을 수행하기 위해서는 StartUP QUANT의 Class 04까지 완료가 되어 있어야 합니다.
•
오늘(2024년 8월 23일) 전체적으로 알 수 없는 시장의 흐름속에, 유한양행이 급등하고 있습니다.
•
유한양행 관련해서는 폐암약 렉라자가 미FDA에서 통과된 것으로 기사가 나왔습니다.
•
기사는 몇 일 전에 본 것 같은데 주가는 오늘 급등을 했습니다.
•
왜? 호재가 나온날 오르지 않고 지금 올랐을까요.
•
주식 관련해서는, 우리가 정보를 아는 순간 이미 늦은거란 말이 있습니다.
•
뭐 어쨋든, 호재와 주가의 흐름을 살펴 보는 것에 목표가 있습니다.
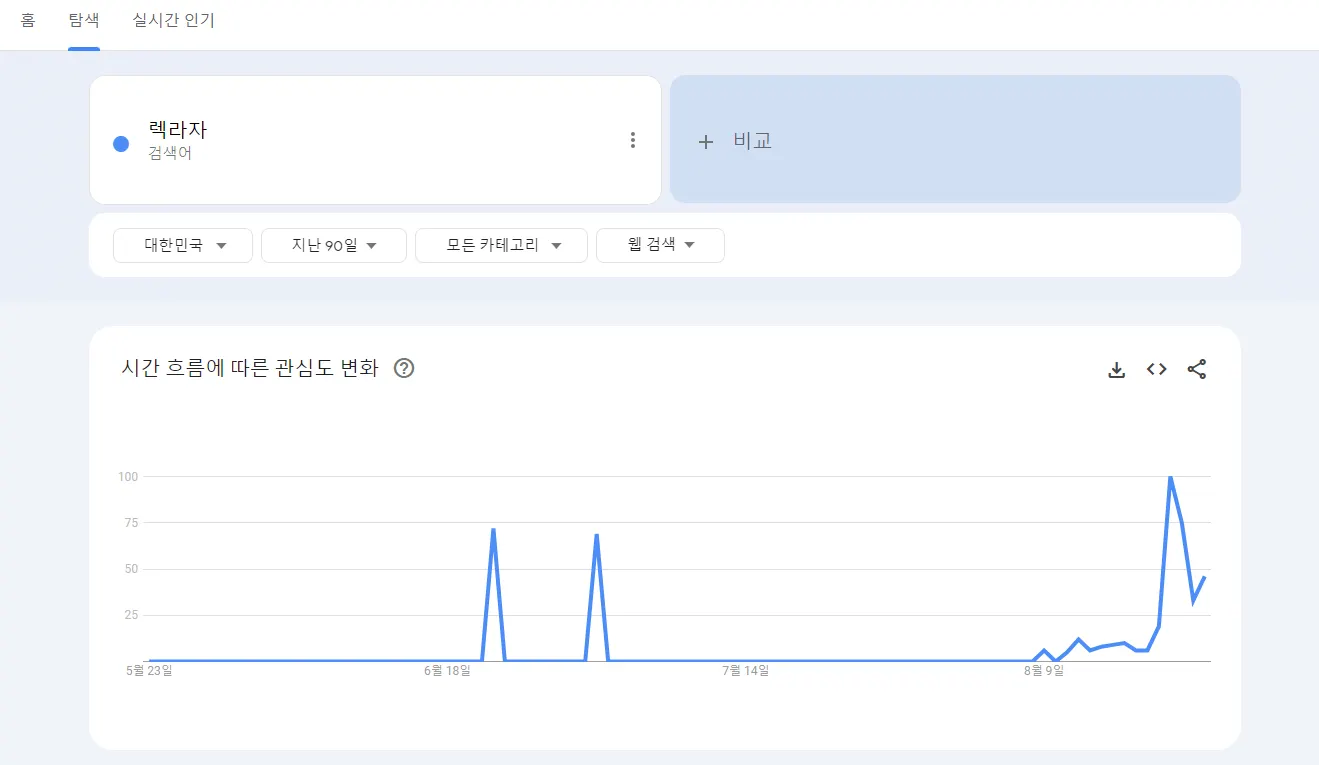
우선 구글 트렌드를 통해 렉라자 검색 트렌드를 확인해봅니다.
오늘 일자로 최근 90일간의 ‘렉라자’ 검색 트렌드를 분석해보면 다음과 같습니다.
•
가장 관심이 높았던 날은 24년 8월 20일이네요. 눈에 뛰는 건, 6월에도 트렌드 수치가 올랐었다는 점입니다.
•
트렌드 결과를 다운로드 합니다.
◦
다운로드 받은 파일의 컬럼 헤더를 Date와 trend로 수정해서 저장합니다.
▪
Date의 첫 글자를 대문자 D로 처리 필요합니다.(주가 데이터와 Merge를 위해)
◦
수정한 파일을 아래 첨부합니다.
•
위에서 첨부한 csv 파일을 다운로드 합니다.
•
Class01에서 만든 파이썬 프로젝트(myStartUPQuant)에 20240823_유한양행_렉라자.py 파일을 신규로 생성합니다.
•
20240823_유한양행_렉라자.py의 기본 골격은 Class 04의 preprocessingMA.py와 같습니다.
•
20240823_유한양행_렉라자.py의 코드를 다음과 같이 작성합니다.
◦
주의! 해당 파이썬 파일이 존재하는 경로에, 위에 첨부한 20240823_렉라자_구글트렌드.csv 파일이 같이 존재해야 합니다.
# QUANTLive\20240823_유한양행_렉라자.py
# Class04의 prepreocessingMA 의 내용을 기본으로 합니다.
import pandas as pd
import fdrCommon
import matplotlib.pyplot as plt
import numpy as np # 과학 계산을 위해 사용, 대규모 다차원 배열과 행렬 연산에 최적화된 기능을 제공
pd.set_option('display.max_columns', None) # df(Dataframe) 출력시 모든 컬럼 출력하도록 처리
pd.set_option('display.width', 1000) # df(Dataframe) 출력시, 한 로우가 따로 출력되지 않도록 충분한 길이 설정
def preprocessing_MA(df):
# 현재 df의 Date 컬럼이 인덱스이자 Date 형태 값으로 구성되어 있음
# 이 경우, 차트로 그릴때 휴일을 알아서 건너뛰고 나오므로, Date를 일부러 문자로 변환 처리
# 인덱스는 순번으로 재처리
df.index = df.index.strftime('%Y-%m-%d') # 'Date' 인덱스를 문자열로 변환
df.reset_index(drop=False, inplace=True) # 인덱스는 순번 재처리(Date 컬럼이 일반 컬럼으로 변경됨)
df['MA20'] = df['Close'].rolling(window=20).mean() # 20일 이동평균
df['MA60'] = df['Close'].rolling(window=60).mean() # 60일 이동평균
df['MA120'] = df['Close'].rolling(window=120).mean() # 120일 이동평균
df['MA200'] = df['Close'].rolling(window=200).mean() # 200일 이동평균
return df
# 변경: df_google 추가함.
def DrawChart(df, showDays):
# df의 내용을 시각화합니다.
df = df.tail(showDays).copy() # df에서 최근 몇 개의 데이터만 잘라냅니다.
# 차트와 서브플롯 생성
fig, (ax1, ax2) = plt.subplots(2, 1, gridspec_kw={'height_ratios': [4, 1]})
# 'Close' 및 이동평균을 ax1에 표시
ax1.plot(df['Date'], df['Close'], label='Close', color='black')
ax1.plot(df['Date'], df['MA20'], label='MA20', color='red', alpha=0.7)
ax1.plot(df['Date'], df['MA60'], label='MA60', color='green', alpha=0.7)
ax1.plot(df['Date'], df['MA120'], label='MA120', color='blue', alpha=0.7)
ax1.plot(df['Date'], df['MA200'], label='MA200', color='purple', alpha=0.7)
ax1.legend(loc='upper left')
ax1.set_title('Stock Price and Moving Averages')
ax1.set_ylabel('Price')
# 변경-5: ax1_twin에 구글 트렌드를 같이 그려주기
ax1_twin = ax1.twinx()
ax1_twin.plot(df['Date'],df['trend'],label='Google Trend',color='orange')
ax1_twin.legend(loc='lower left')
# 'Volume'을 ax2에 표시
ax2.bar(df['Date'], df['Volume'], color='gray', alpha=0.8)
ax2.set_ylabel('Volume')
# xtick이 너무 많아서 안보이므로 10개만 보이도록 처리.
day_xticks = np.linspace(0, len(df['Date']) - 1, 10, dtype=int)
ax1.set_xticks(day_xticks)
ax1.set_xticklabels(df['Date'].iloc[day_xticks])
ax2.set_xticks(day_xticks)
ax2.set_xticklabels(df['Date'].iloc[day_xticks])
plt.show()
# 변경-1: Symbol을 유한양행의 종목코드로 변경
symbol = "000100" # 유한양행
df = fdrCommon.getPriceHistory(symbol, '', 200) # fdr공통모듈을 통해 티커의 주가 정보 가져오기
df_MA = preprocessing_MA(df)
print(df_MA.head(10))
# 변경-2: 20240823_렉라자_구글트렌드.csv 파일 읽어들이기.
df_google = pd.read_csv('20240823_렉라자_구글트렌드.csv', encoding='cp949')
print(df_google.head(10))
# 변경-3: df_MA와 df_google을 Date 컬럼을 기준으로 병합
# how='left'는 df_MA의 모든 데이터를 유지하고 해당하는 df_google의 데이터를 추가함
# on='Date'는 두 DataFrame이 'Date' 컬럼을 기준으로 병합됨을 의미함
df_MA_merged = df_MA.merge(df_google[['Date', 'trend']], on='Date', how='left')
print(df_MA_merged.head()) # 병합된 데이터의 처음 몇 줄을 출력하여 확인
# 변경-4: df_MA_merged 를 넘기도록 변경
DrawChart(df_MA_merged, 200)
SQL
복사
•
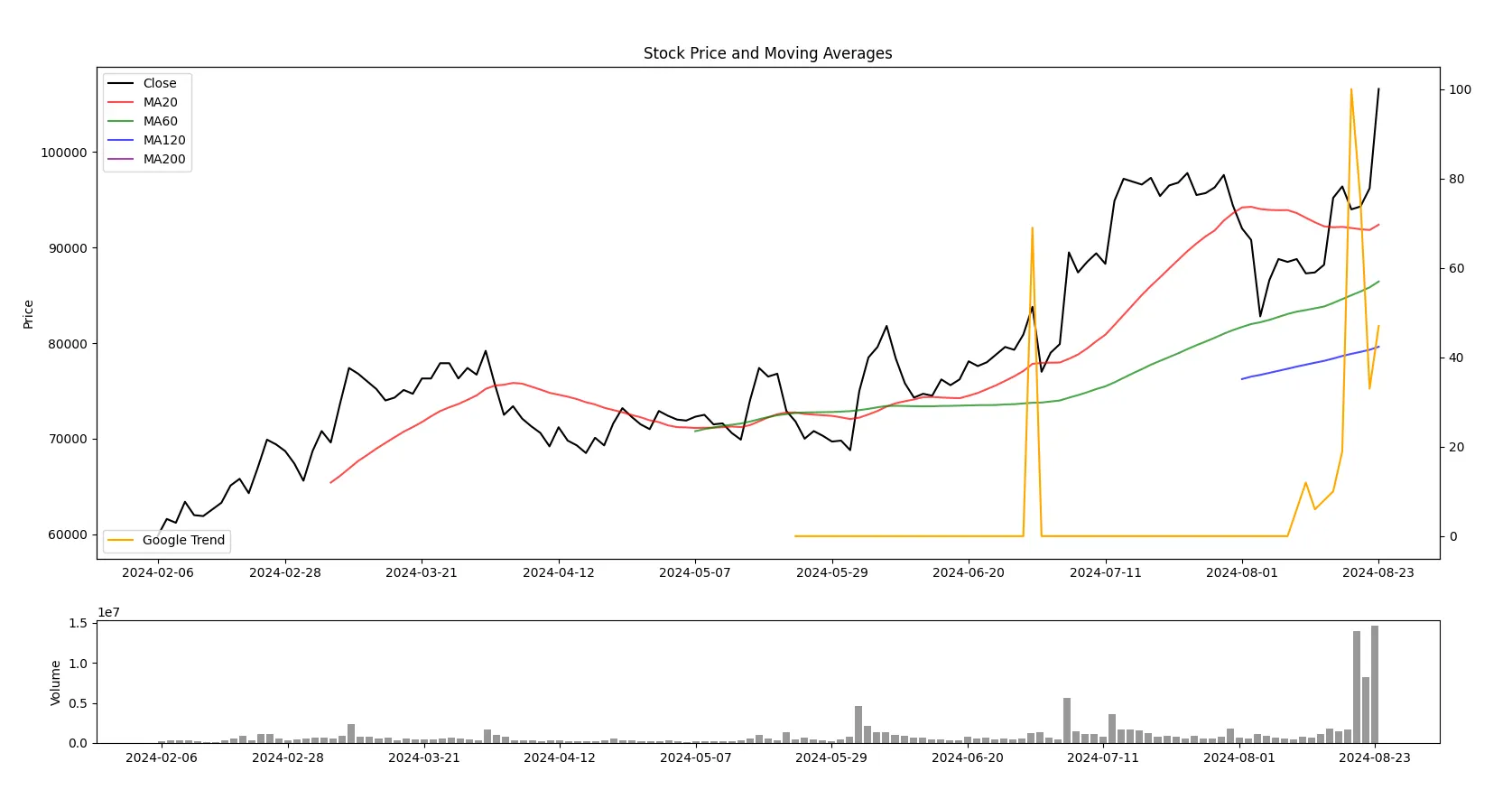
위 파이썬 코드를 실행하면 다음과 같은 결과를 볼 수 있습니다.
◦
오렌지 색이 구글 트렌드 수치입니다.
◦
이처럼 파이썬을 이용하면 생각보다 쉽게(?) 구글 트렌드와 주가 흐름을 겹쳐서 확인할 수 있습니다.